

99藏书网是一个免费的在线图书阅读网站,网站中分享的均是已出版的书籍,内容还是很多的,而且,校对和排版都非常好。但是,网站不提供下载,而且,右键的复制粘贴也被禁用了。个人比较喜欢看txt电子书,so,咱们写个爬虫来把自己想看的书爬下来吧。
目标分析
- 图书列表
网站图书分类下会显示所有的图书列表,分析链接后发现所有的图书链接均为http://www.99lib.net/book/8947/index.htm这样的格式,其中8947为图书编号,从1-8947。
仔细查看列表,每一项中包括,图书的书名,作者,分类,标签以及书籍的简介。
为了方便以后功能添加,我们提取书籍的书名,作者,书籍的目录链接以及分类信息,并保存中一个文件中。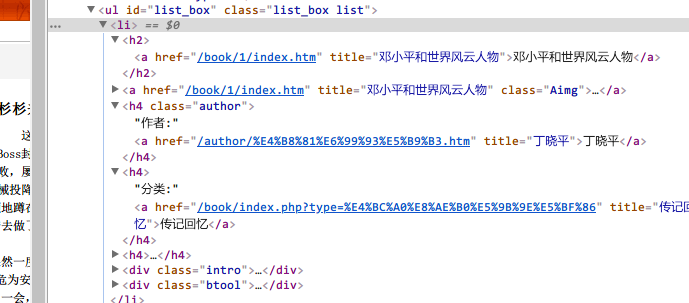
我们使用chrome开发者工具,定位发现书籍列表为id为list_box的ul列表中。其中,每一项li的中的h2标签中的a标签中包含书籍的目录链接和书名信息。
在class为author的h4标签中包含书籍的作者信息,它是下一个h4标签中包含书籍分类信息。 - 章节列表
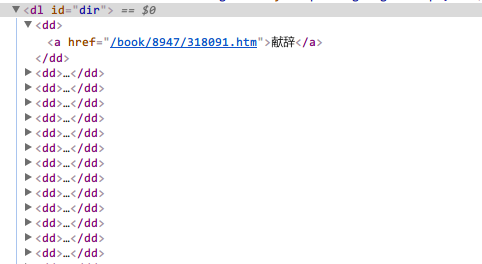
我们使用chrome开发者工具,定位发现书籍的各章节链接为id为dir的dl列表中dd标签下的a链接中 - 章节内容
任意打开一个章节,从chrom开发者工具中,我们发现章节的所有内容都存放在id为content的div标签中。
项目实施
首先我们把所有的图书信息保存为一个json文件。这里我们使用requests和beautifulsoup库来实现。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51import requests
from bs4 import BeautifulSoup
import json
# 网站的根地址
base_url = 'http://www.99lib.net'
# 书目页的url模版
url = base_url + '/book/index.php?page={page}'
# 书籍的总页数
total_page = 1
page = 0
# 由于网站服务器中美国,这里我设置了代理
proxie = {
'http': 'http://127.0.0.1:1080',
}
# 以追加的方式序列化存储为json并写入文件
with open('book_list.json','a',encoding='utf-8') as f:
f.write('[\n')
# 获取所有书目信息
while True:
page += 1
# 如果页面超出总页数,则停止循环
if page > total_page:
break
# 开始爬取链接
print('fecth:' + url.format(page=page))
res = requests.get(url.format(page=page),proxies=proxie)
# 解析爬取到的html
html = BeautifulSoup(res.text, 'html.parser')
# 获取到总页数
total_page = int(html.select('.total')[0].text[-3:])
# 提取每页书名列表
name_list = html.select('#list_box h2 a')
# 提取每页分类列表
categories = html.select('.author')
lenth = len(name_list)
# 一个简单的循环来生成书籍信息
for j in range(0,lenth):
# 一个空字典,每个字典代表一本图书
t = {}
# 在字典中添加书籍的各项信息
t['name'] = name_list[j].string
t['link'] = base_url + name_list[j]['href']
t['aurhor'] = categories[j].a.string if categories[j].a != None else 'none'
t['category'] = categories[j].next_sibling.a.string
# 这里需要注意:不提供ensure_ascii=False参数将导致最终生成的文件中unicode编码的文字以\u4e2d\u6587这样的形式显示
if j != lenth - 1:
f.write(json.dumps(t,ensure_ascii=False) + ',\n')
else:
f.write(json.dumps(t,ensure_ascii=False) + '\n')
f.write(']\n')
程序执行时的效果如图。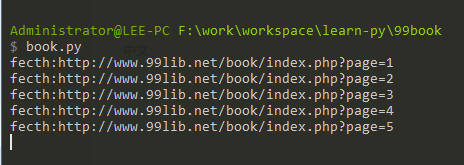
程序执行后会在当前目录下生成book_list.json文件,文件打开后内容如图所示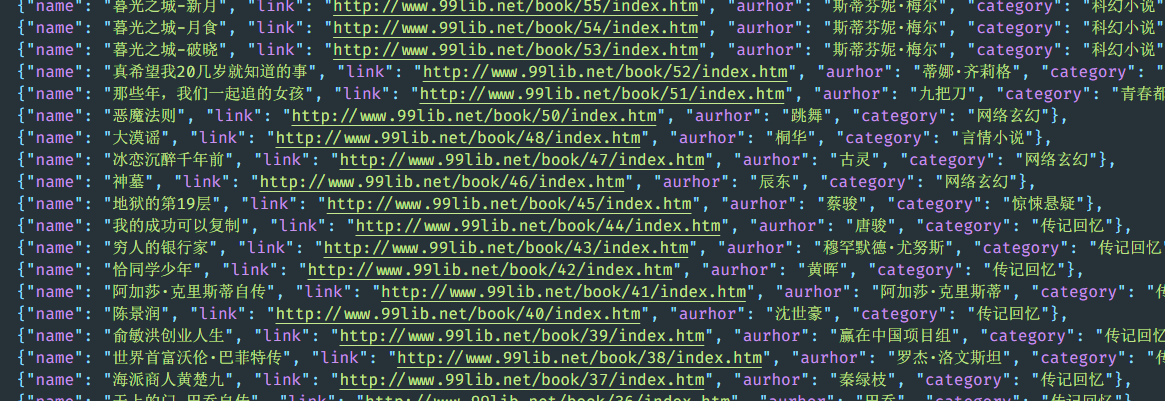
咱们下期再见!
本文所提供内容仅供学习测试用途,请勿用作其他用途。