

前情提示
上篇文章Python爬虫之99藏书网(上)中,我们获取了99藏书网中所有的图书信息并存储在了一个名为book_list.json的文件中。
现在我们继续我们的工作!
目标确定
首先,我们要确定我们的任务目标。我的想法是程序开始运行后,输入我们要爬取的图书名称,如果图书存在,则开始爬取小说,并最终生成txt文档;如果不存在,则给出提示并退出程序。
过程分析
由于上篇文章已经分析了具体的内容,所以不再赘述。
开始实施
获取章节目录
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# 获取章节列表
def get_chapter_list(self, book_link):
# url 前缀
baseurl = 'http://www.99lib.net'
# 代理
proxie = {
'http': 'http://127.0.0.1:1080',
}
# 提示正在获取章节列表
print('获取章节列表中...')
# 发起请求
res = requests.get(book_link,proxies=proxie)
# 获取响应内容
html = BeautifulSoup(res.text, 'html.parser')
# 筛选出id为dir的元素中所有的a链接
a_list = html.select('#dir')[0].find_all('a')
# 获取所有的a链接的内容与前缀组成完整的url地址列表
link_list = list(map(lambda x: baseurl + x['href'],a_list))
# 提示该图书总的章节数
print('本书共有' + str(len(link_list)) + '章')
# 将最终获取的章节链接列表返回
return link_list获取章节内容
为了方便调试,我们先随便找个章节测试一下,地址是http://www.99lib.net/book/8953/318287.htm
打开页面后内容如图
测试代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14# 引入相关模块
import requests
from bs4 import BeautifulSoup
# 测试地址
url = 'http://www.99lib.net/book/8953/318287.htm'
# 发起请求获取响应内容
res = requests.get(url)
html = BeautifulSoup(res.text, 'html.parser')
# 获取段落内容列表
contents = html.select('#content')[0].strings
# 将列表逐行打印
for content in contents:
print(content)
结果如下: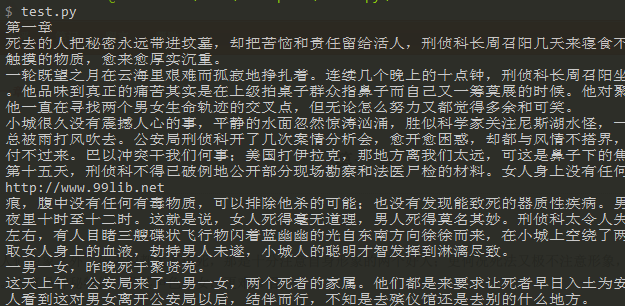
这里我们会发现一个问题,获取到的章节内容的段落是乱序的,但是页面上显示的是没问题的。我们来找找原因。
问题分析
我们来分析内容乱序的原因,在浏览器中打开章节页面,ctrl + u打开网页源代码,我们看到的结果是这样的
我们再F12打开chrom开发者工具,看到的内容是这样的
和这样的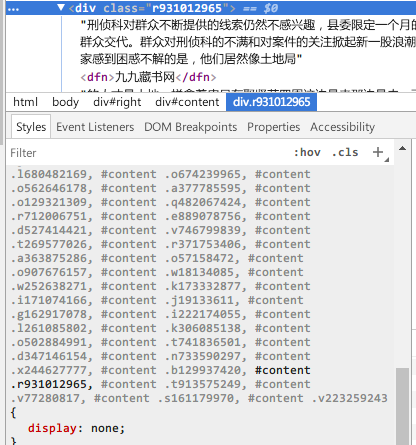
可以看出,开发者工具中看到的内容仍然是乱序的,而且其中所有的段落都添加了一个随机生成的类名,而且通过display属性进行了显示和隐藏,最终中页面上显示出正确排序的段落。
这是个很棘手的问题。我们需要知道这个结果是怎样生成的?
既然不是在源代码中,那么应该是有js动态加载的,那么是用ajax动态获取的吗?
验证一下,在开发者工具中切换到network选项,刷新页面,再点击xhr,我们发现有一个ajax请求,点击,再切换到response选项,我们发现该请求没有任何响应。如下图: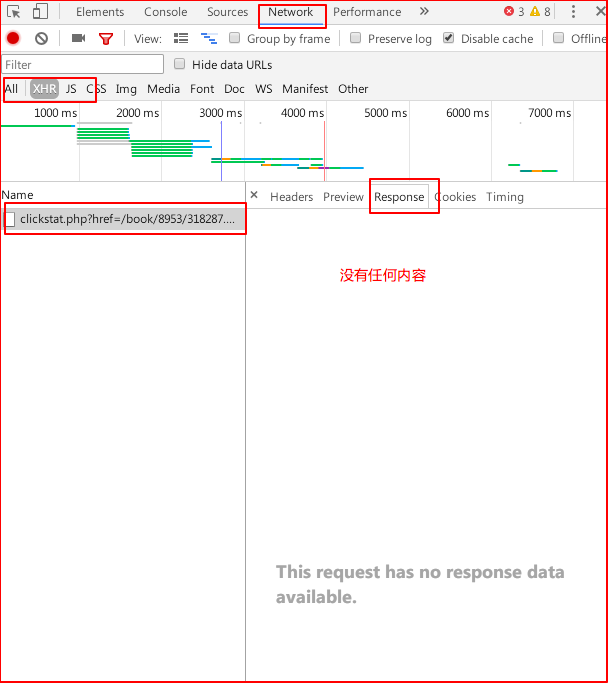
这是个dead end!
既然不是ajax,那么要不是后台,要么就是js动态生成。
如果是后台,我们看不到后台代码,dead!
js的话,共有以下,个人水平有限,还原不了,dead!见下图。
那么我们来换个思路,不论怎么生成的页面,我们知道,最终用户看到的页面上显示的是完整且正常的内容。有没有办法让我们直接获取页面上显示的内容呢?
答案当然是肯定的!!!
以下内容摘至之后专栏从零开始写Python爬虫
Selenium的介绍:
为什么我们要使用这个包呢?在写Python爬虫的时候,最麻烦的不是那些海量的静态网站,而是那些通过JavaScript获取数据的站点。Python本身对js的支持就不好,所以就有良心的开发者来做贡献了,这就是Selenium,他本身可以模拟真实的浏览器,浏览器所具有的功能他一个都不拉下,加载js更是小菜了。
浏览器的选择:
在写爬虫的时候,用到最多的就是Selenium的Webdriver,
当然,webdriver也不可能支持所有的浏览器,让我们看看他支持哪些浏览器吧:1
2
3
4
5
6
7
8
9
10
11
12
13PACKAGE CONTENTS
android (package)
blackberry (package)
chrome (package)
common (package)
edge (package)
firefox (package)
ie (package)
opera (package)
phantomjs (package)
remote (package)
safari (package)
support (package)
可以看到,Selenium支持的浏览器还是非常丰富的,
无论是移动端的Android、blackberry
还是我们电脑常用的Chrome,Safari,Firefox。
然而,在写爬虫的 时候,我推荐使用PhantomJS:
PhantomJS是一个而基于webkit的服务器端的JS API。
他全面支持各种原生的Web标准:DOM处理、CSS选择器、JSON、Canvas和SVG。最重要的是他是一个没有GUI的程序,
也就意味着他可以省去大量的加载图形界面的时间。
有人曾经测试过,使用Selenium模块调用上述浏览器,PhantomJS的速度是第一名哦~
第二和第三是chrome和ie。
以上内容可以概括为selenium可以让我们使用一个无界面的浏览器来打开网页,然后获取网页上的信息,就如同我们正常浏览网页一样。
不过,上面作者推荐使用PhantomJS,实际使用中发现,最新版的selenium即将去除对PhantomJS的支持,而且chrome也推出了自己的无头(通俗来讲就是无界面)浏览器。因此,在项目中我们使用chrome。
实际使用发现,无头chrome的速度好像比PhantomJS的速度还是要快上那么一丢丢的。
重新获取章节内容
首先请pip安装selenium。
然后我们需要下载ChromeDriver
下载最新版就可以了。
看代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53# 引入webdriver模块
from selenium import webdriver
# 引入时间模块
import time
# Keys 是用作关键词输入
from selenium.webdriver.common.keys import Keys
# 导入chrome配置选项
from selenium.webdriver.chrome.options import Options
# 生成chrome配置选项
chrome_options = Options()
# 设置chrome浏览器为无头形式
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 设置chrome浏览器日志级别为最低,减少控制台输出信息
chrome_options.add_argument('log-level=3')
# 【可选配置】设置chrome浏览器代理
# chrome_options.add_argument("--proxy-server=http://127.0.0.1:1080")
# 指定chromedriver的路径
chrome_position = 'F:\\chromedriver\\chromedriver.exe'
# 获取章节内容
def get_content(self, link_list):
# 开启chrome浏览器
# executable_path为chromedriver的路径
# chrome_options为chrome配置选项
driver = webdriver.Chrome(executable_path=chrome_position,chrome_options=chrome_options)
# 起始页
page = 0
# 总页数
total = len(link_list)
# 遍历章节链接列表
for link in link_list:
page += 1
# 打开章节页面
driver.get(link)
# 等待一段时间,让网页加载完成
driver.implicitly_wait(1)
循环向下拖动页面滚动条40次
for i in range(40):
# 拖动滚动条到页面底部
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")
# 每次拖动结束后等待0.02秒,根据自己的网速情况自行设置
time.sleep(0.02)
# 获取到章节内容
elem = driver.find_element_by_id("content").text
# 调用保存函数将内容保存
self.save_content(elem, self.name)
# print(elem.text)
# 提升当前章节已下载完成
print('第' + str(page) + '章下载完毕/共' + str(total) + '章')
# 提示图书下载完成
print('图书下载完成!')
关闭无头浏览器
driver.quit()
完整程序如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79import json
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
import time
# Keys 是用作关键词输入
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('log-level=3')
# chrome_options.add_argument("--proxy-server=http://127.0.0.1:1080")
chrome_position = 'F:\\chromedriver\\chromedriver.exe'
class GetBook(object):
def __init__(self,name):
self.name = name
self.books = self.get_book_list()
self.result = self.get_book_link(self.books,name)
if self.result == None:
return
link_list = self.get_chapter_list(self.result)
self.get_content(link_list)
# 获取书名列表
def get_book_list(self):
with open('book_list.json','r',encoding='utf-8') as f:
t = json.load(f)
return t
# 获取被查询的图书链接
def get_book_link(self,books,name):
for book in books:
if name == book['name']:
print(book['link'])
return book['link']
print('你所查询的书名不存在!')
return None
# 获取章节列表
def get_chapter_list(self, book_link):
baseurl = 'http://www.99lib.net'
proxie = {
'http': 'http://127.0.0.1:1080',
}
print('获取章节列表中...')
res = requests.get(book_link,proxies=proxie)
html = BeautifulSoup(res.text, 'html.parser')
a_list = html.select('#dir')[0].find_all('a')
link_list = list(map(lambda x: baseurl + x['href'],a_list))
print('本书共有' + str(len(link_list)) + '章')
return link_list
# 获取章节内容
def get_content(self, link_list):
driver = webdriver.Chrome(executable_path=chrome_position,chrome_options=chrome_options)
page = 0
total = len(link_list)
for link in link_list:
page += 1
driver.get(link)
# 等待一段时间
driver.implicitly_wait(1)
for i in range(40):
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(0.02)
# 找到name为"q"的元素
elem = driver.find_element_by_id("content").text
self.save_content(elem, self.name)
# print(elem.text)
print('第' + str(page) + '章下载完毕/共' + str(total) + '章')
print('图书下载完成!')
driver.quit()
def save_content(self, content, name):
with open(name + '.txt', 'a', encoding="utf-8") as f:
f.write(content + '\n')
if __name__ == '__main__':
book_name = input('请输入书名:')
GetBook(book_name)
本文所提供内容仅供学习测试用途,请勿用作其他用途。